Bank Policy Assistant through RAG
A privacy-first AI assistant that gives bank employees instant access to internal policy documents without a single byte of data leaving the corporate firewall.
1. Context and problem
In highly regulated industries like banking, employees constantly navigate dense, complex policy documents from Account Opening Procedures to Compliance Guidelines. Finding specific, accurate information quickly is a significant operational bottleneck.
I explicitly chose Retrieval-Augmented Generation (RAG) for this architecture. RAG dynamically searches a database for the exact relevant paragraphs and feeds them to the LLM at the moment of the user’s query [1]. This ensures the AI’s answers are always based on the most current, approved documents.
However, bringing RAG to an enterprise introduces a critical business constraint: Data Privacy.
Privacy vulnerability in the RAG pipeline
To understand this constraint, consider the procedure of a RAG pipeline:
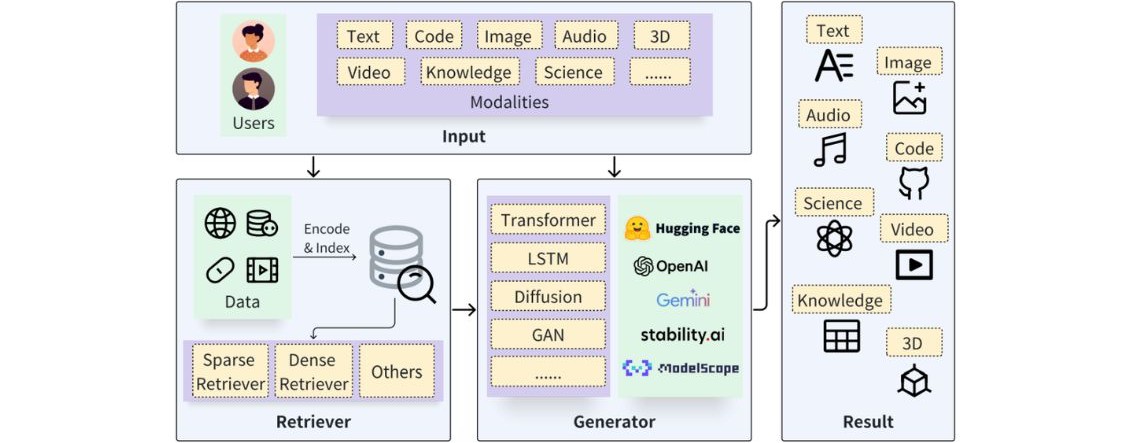
- Chunking: The system breaks a massive PDF into smaller paragraph-sized chunks.
- Embedding: These text chunks are passed through an embedding model, converting words into mathematical vectors.
- Storage: These vectors are saved in a Vector Database.
- Generation: When a user asks a question, it is also vectorized, the database finds matching document numbers, and the raw text is sent to an LLM to generate an answer.
The vulnerability occurs at steps 2 and 4. If a commercial, closed-source cloud API (like OpenAI’s or Anthropic’s) is used for vectorization or generation, bank internal policies must leave the corporate firewall and be processed on external servers. In the financial sector, this introduces severe data leakage risks and violates compliance frameworks like SOC 2, GDPR, and GLBA [2].
The goal of this project was to build a Bank Policy Assistant that:
- Provides instant access to internal documents while neutralizing this exact vulnerability
- Balancing a highly secure backend with a frictionless user experience.
2. Solution architecture
To achieve this, I decoupled the processing pipeline, prioritizing local, air-gapped execution for all sensitive data-processing steps:

- Document Parsing: I utilized
PyMuPDF4LLMto process PDFs, converting complex corporate layouts and tables into clean Markdown, preserving grid structure so the LLM can accurately understand data relationships. - Vectorization: Instead of a commercial API, I implemented an open-source, self-hosted model (
all-MiniLM-L6-v2via HuggingFace), ensuring no document data leaves the host server during ingestion [3]. - Vector Database:
ChromaDBis used for lightweight, persistent vector storage. - Generation: I integrated Groq API for high-speed conversational output via specialized Language Processing Units (LPUs).
- Frontend UI: A custom Streamlit interface, heavily modified from the default configuration to deliver a clean, enterprise-grade UX.
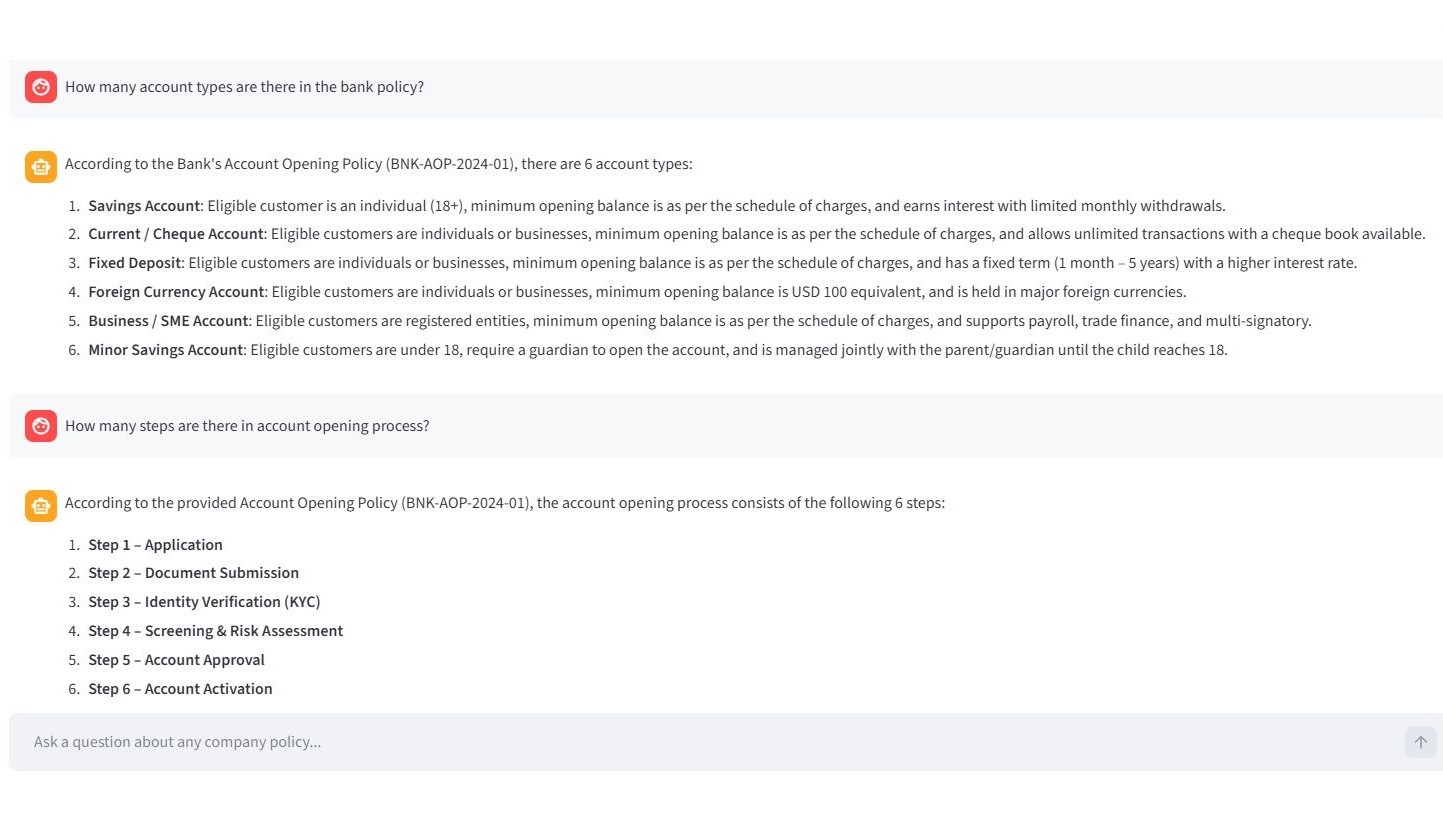
Below is an example of a question and system response for the account opening policy.
3. Challenges across the development lifecycle
Challenge 1 — The “out-of-bounds” hallucination
During early testing, when asked a policy question not explicitly covered in the bank’s documents, the LLM would confidently hallucinate an answer based on generic banking practices from its training data [4]. In a regulated enterprise, an AI guessing a policy is a catastrophic compliance risk.
The following example illustrates this case.
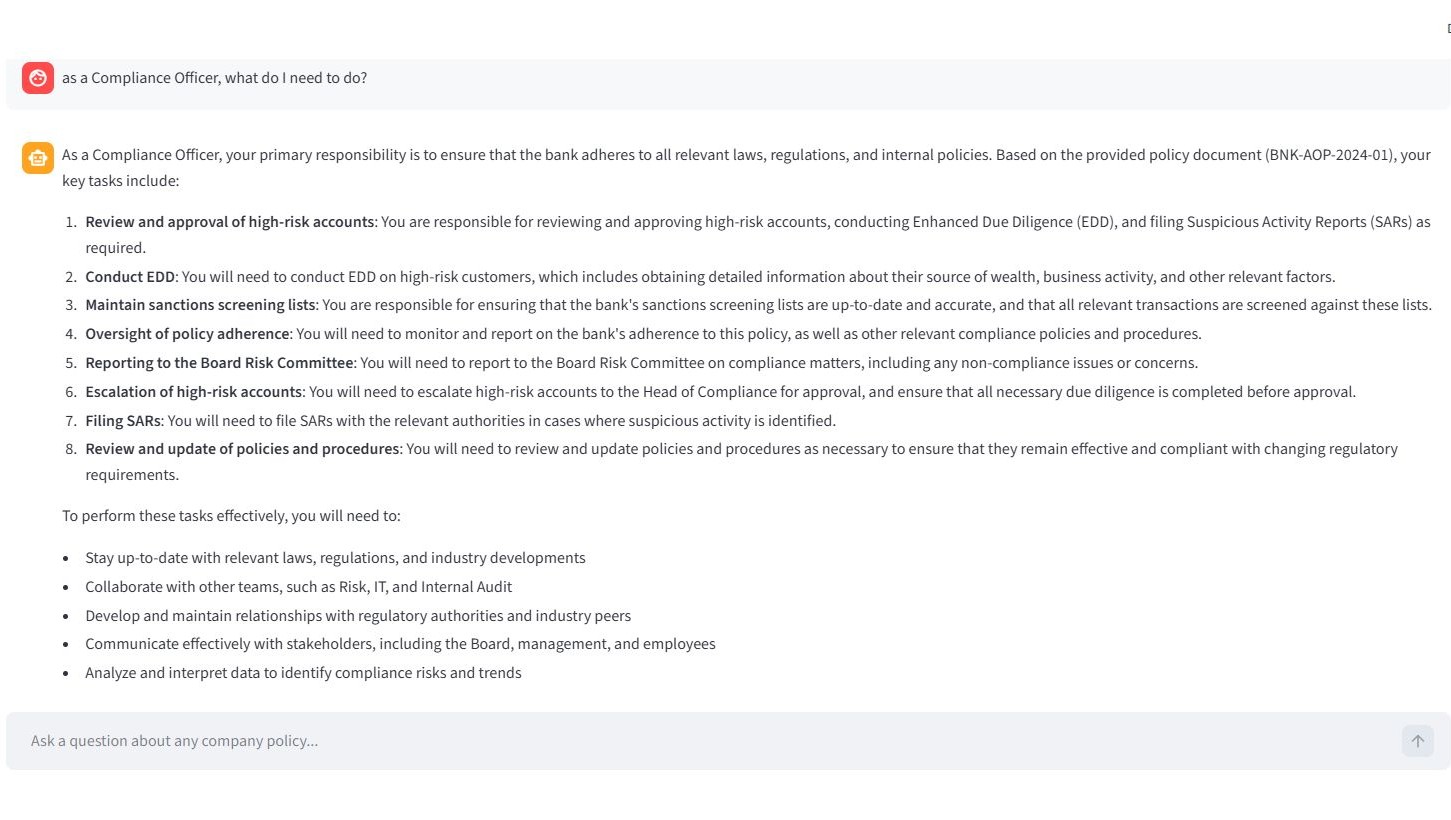 Solution: I implemented a two-pronged defense using parameter tuning and prompt engineering.
First, I hardcoded the LLM’s
Solution: I implemented a two-pronged defense using parameter tuning and prompt engineering.
First, I hardcoded the LLM’s temperature to 0. By forcing temperature to absolute zero, I stripped the model of its creative autonomy, making outputs strictly deterministic.
Second, I rewrote the core system prompt to explicitly restrict the model’s universe of knowledge:
Your ONLY job is to extract exact facts from the provided context.
CRITICAL RULES:
1. STRICT GROUNDING: Answer ONLY using the information explicitly written in the Context. Do NOT add general knowledge, industry best practices, or 'helpful advice' that is not in the text. If the text does not say it, you must not say it.
2. ENTITY ISOLATION: Pay extreme attention to specific job titles. For example ff the user asks about 'Compliance Officer', do NOT include responsibilities assigned to the 'Head of Compliance', 'Risk Manager', or any other role.
3. NO EXTRAPOLATION: Do not infer how a job should be done. Just list the duties stated.
4. EVIDENCE: Whenever possible, use the exact phrasing from the policy.Below is the LLM’s revised response following these changes.
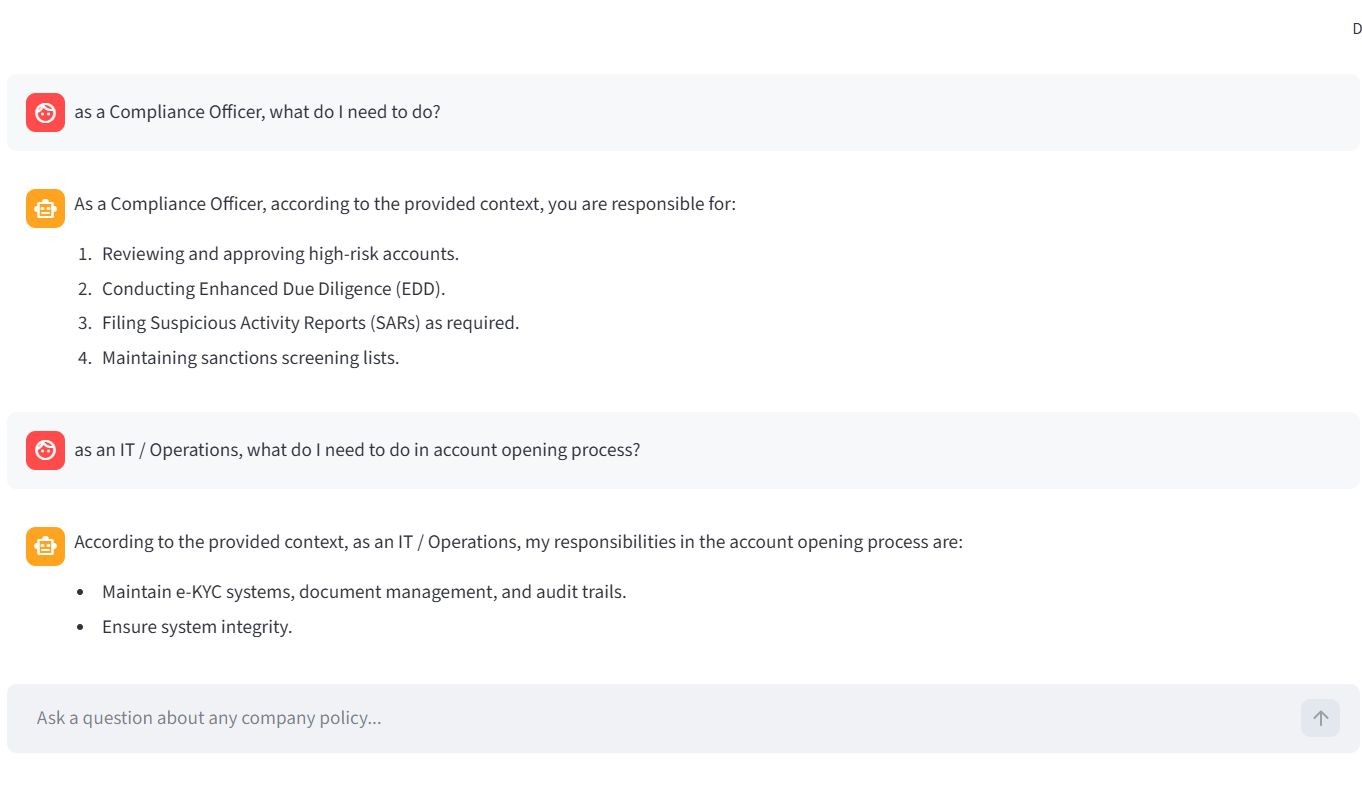
Challenge 2 — Stateless LLM
Out of the box, LLMs have no memory of a conversation. Even with RAG providing document context, the model struggles with follow-up questions due to the absence of prior interaction awareness. See the example below.
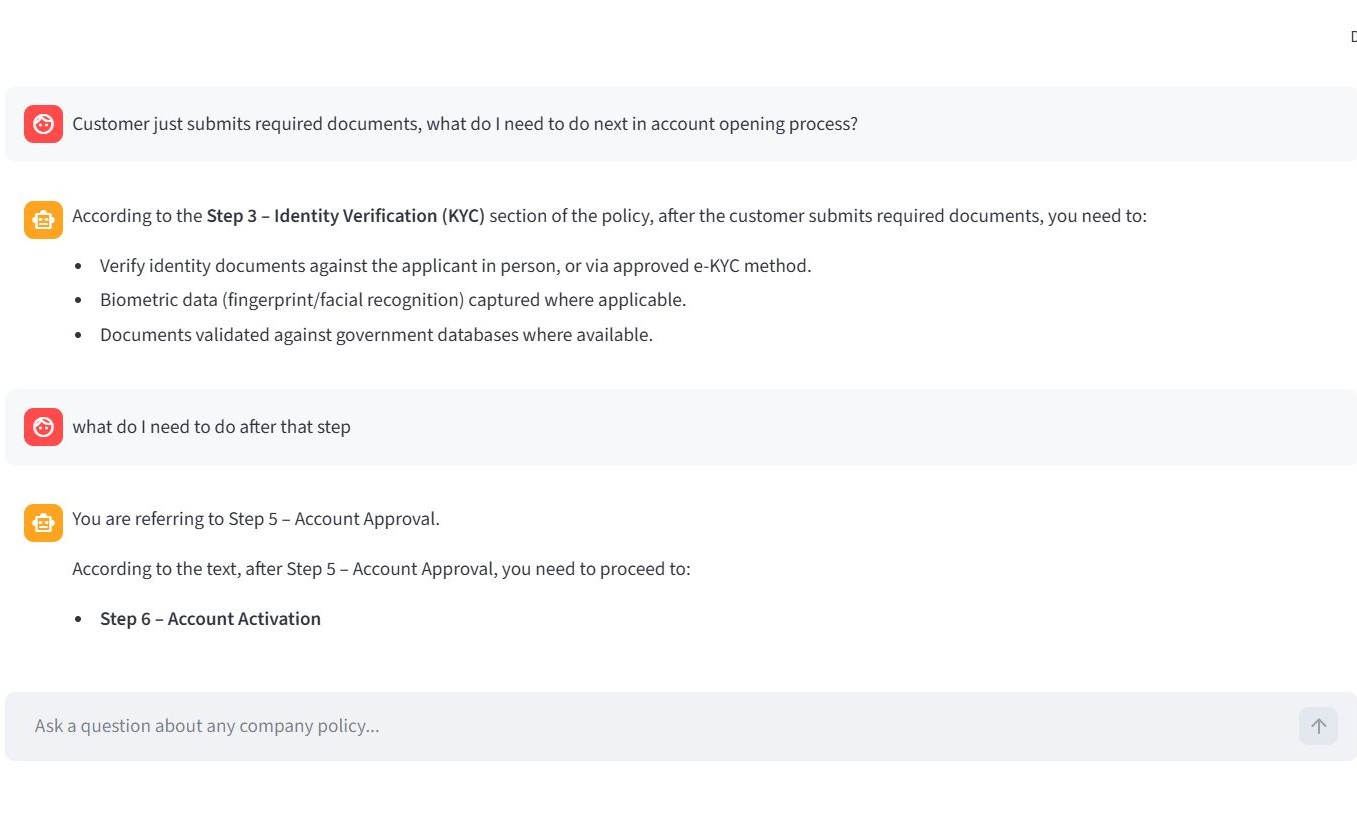 Solution: I engineered conversational memory directly into the application loop. Using Streamlit’s
Solution: I engineered conversational memory directly into the application loop. Using Streamlit’s session_state, I cached the dialogue. Before sending each new prompt, logic iterates through this cache, formats prior interactions into LangChain HumanMessage and AIMessage constructs, and injects the entire transcript back into the model’s context window.
This grounded the model and enabled seamless conversational continuity, as illustrated in the examples below.
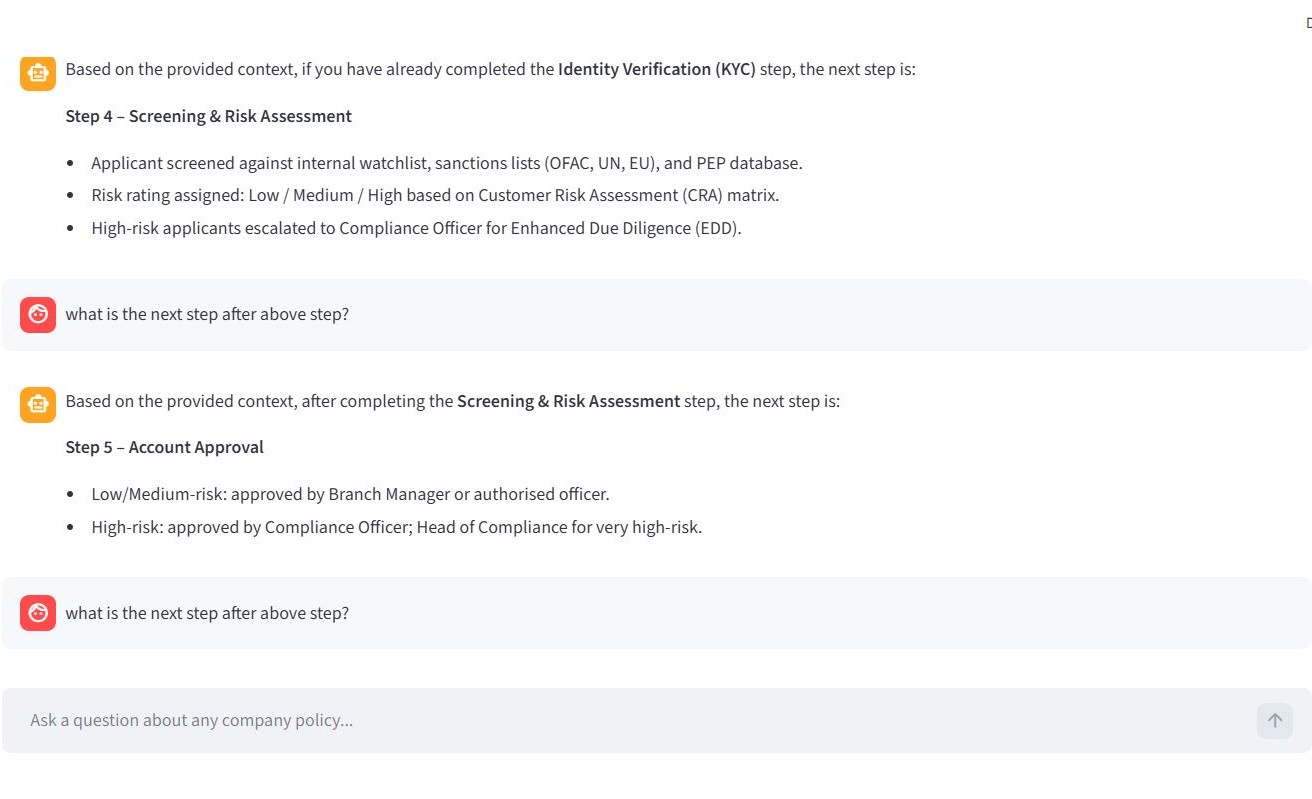
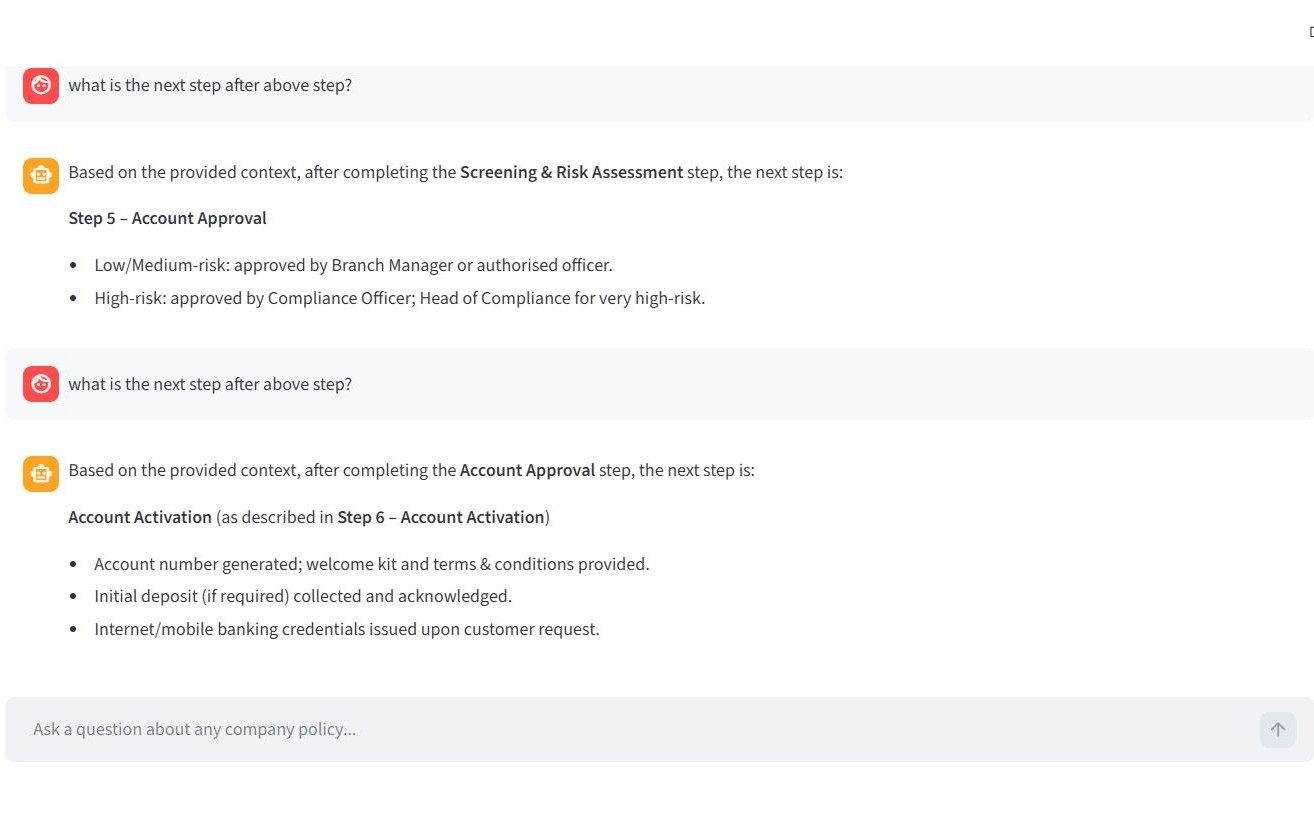
Challenge 3 — Inference latency
During early development, I ran the entire pipeline, including the generation LLM, locally via Ollama. While this was completely secure, passing large blocks of retrieved PDF text into a local model running on standard consumer hardware created severe inference latency (4 - 5 minutes to generate a response).
Solution: I deliberately decoupled the architecture. Vectorization stays strictly local to protect document ingestion, while the final text generation step routes through the Groq API.
Groq’s LPUs are engineered specifically for ultra-fast LLM inference, reducing response time from minutes to milliseconds.
4. Current Application vs. Production-Grade Banking Deployment
Due to resource constraints, the current implementation differs from a real-world bank deployment, as detailed below:
| Component | This Project | Real-World Bank |
|---|---|---|
| Vector Embeddings | Self-hosted HuggingFace (all-MiniLM-L6-v2) | Private endpoint (e.g. Azure OpenAI) inside corporate firewall |
| Vector Database | ChromaDB (local SQLite) | Client-server vector DB for millions of documents |
| LLM Generation | Groq Cloud API (free tier) | Private VPC or fully localized LLM on internal GPU nodes |
| Infrastructure | Streamlit Community Cloud | Dockerized containers on internal Kubernetes clusters |
Application limitations
- Rate limiting: Because the system relies on a free-tier Groq API key, concurrent users submitting queries simultaneously may experience brief rate-limit delays.
- Session volatility: Streamlit Cloud is designed to sleep after periods of inactivity. A hard refresh of the browser will clear the conversational memory history.
5. Try it yourself
I invite you to test the application and evaluate the retrieval quality firsthand.
How to evaluate:
- Ask specific questions about account creation, required documentation, or compliance thresholds.
- Test the guardrails: Ask something unrelated to banking (e.g. “What is the capital of France?”) to see strict prompt engineering in action.
- Test the memory: Ask a follow-up question without repeating the subject (e.g. “Does that apply to corporate accounts too?”).
- Use the sidebar’s PDF viewer to cross-reference AI answers directly with the source document.
References
- Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
- OWASP Foundation (2025). OWASP Top 10 for Large Language Model Applications.
- Forbes Tech Council (2024). Transforming Businesses With LLMs: Risks And Use Cases.
- Gao, Y., et al. (2023). Retrieval-Augmented Generation for Large Language Models: A Survey.